MsSQL Clustered 연구 노트
MsSQL의 테이블은 2가지 데이터 저장 자료구조를 가지고 있다.
하나는 데이터를 비어있는 Page에 데이터를 담는 Heap 구조와 Clustered Key 값을 가지고 정렬하여 저장하는 Clustered 구조를 가지고 있다.
이번에 작성하는 MsSQL Clustered 연구노트에는 Heap과 Clustered의 데이터가 저장되는 자료구조와 각 구조의 차이에 대해서 한번 Page단위까지 찾아가 보도록하겠다.
테스트를 위해 파일 그룹과 ndf파일을 분리하여 생성하였다.

Table을 위치할 DATA 파일 그룹과 Index를 각각 위치시킬 INDEX_01 ~ INDEX_03 파일 그룹을 생성하여, 데이터의 변화 과정에 대해서 확인해보도록 하겠다.
Test Table 만들기
테스트를 위한 테이블을 생성하는데, BAN_DATA라는 파일그룹에 테이블을 생성하도록 한다.
-- Table 생성
create table XTMP_TEST_IDX (
CL_NO int not null, -- 4byte
PK_NO int not null identity(1, 1), -- 4 byte
IX_NO int, -- 4 byte
CTS char(500), -- 500 byte
INS_DTM datetime not null default getdate() -- 8 byte
) on DATA
INDEX_01 파일그룹에 논클러스터 인덱스를 생성하도록 한다.
-- 논클러스터 인덱스 생성
create nonclustered index X_DTM_IDX on XTMP_TEST_IDX (IX_NO) on INDEX_01;
데이터를 Insert 하고 새로운 Object를 추가해가며 구조를 확인해보도록 하자.
Data Insert
반복문을 통해 데이터를 Insert해보자
/* 테스트 데이터 Insert */
declare @cnt int = 0
declare @rd_cnt int = 10
while @cnt < 50000
begin
-- 1 ~ 10 랜덤 insert
insert into XTMP_TEST_IDX (cl_no,
ix_no,
cts)
values (cast(rand() * @rd_cnt as int) + 1,
cast(rand() * 30 as int) + 1,
'인덱스 테스트용 테이블입니다. 데이터를 insert합니다.')
set @cnt = @cnt + 1
end조금 랜덤한 값을 넣고 싶어 위와 같이 쿼리를 작성하여 총 5만건의 데이터를 입력하였다.

해당 반복문을 실행하여 데이터를 Insert한 결과 용량의 변화는 아래와 같다.

테이블이 위치한 DATA 파일그룹의 파일의 크기가 커졌으며, Index가 위치한 INDEX_01의 파일 그룹의 파일이 커진 것을 확인 할 수 있다.
Heap Table의 Data 저장구조
아래의 시스템 뷰를 활용하여, 생성한 테이블의 인덱스 정보를 확인해보자.
select *
from SYS.SYSINDEXES with(nolock)
where id = object_id('XTMP_TEST_IDX')
여러가지 정보를 알 수 있는 시스템뷰이지만 지금 우리에게 필요한 것은 indid라는 컬럼이다.
INDEX_ID를 줄인 것 같은 컬럼명으로 0은 Heap Table을 뜻하며, 1은 Clustered Index를 뜻한다.
데이터의 저장구조가 Heap인지 Clustered인지의 차이이며, 당연하게도 0과 1의 값은 공존 할 수 없다.
나머지 2~255는 일반적인 인덱스를 가리킨다.
Data Page 알아보기
MsSQL의 데이터는 Page 라는 단위로 저장이 된다. 우리는 데이터가 저장되는 Page 까지 내려가 Heap Table의 저장구조를 확인해보도록 하자.
당연하게도 데이터는 Heap영역에 있을 것이라는 것을 알 수 있다. 위에서 확인해본 indid를 활용하여, 해당 페이지를 조회해보자.
-- page 정보 조회
select allocated_page_file_id, -- File ID
allocated_page_page_id, -- Page ID
previous_page_file_id, -- 이전 File ID
previous_page_page_id, -- 이전 Page ID
next_page_file_id, -- 다음 File ID
next_page_page_id, -- 다음 Page ID
page_level, -- Page LV ( 0 : leaf page)
page_type_desc, -- Page 형태
extent_file_id,
extent_page_id,
page_type
from SYS.DM_DB_DATABASE_PAGE_ALLOCATIONS(db_id('BAN_DB'), -- db id
object_id('XTMP_TEST_IDX'), -- table id
0, -- index id
null, -- partition id
'detailed') -- limited : 제한적 정보 / detailed : 많은 정보
order by page_level desc,
isnull(page_type_desc, 'XX') desc,
allocated_page_file_id,
allocated_page_page_id위 쿼리를 통해 테이블의 Page정보를 확인 할 수 있다. index id 값에 Heap ID값인 0을 넣어 확인하였다.
참고로 null을 넣을 경우 해당 테이블의 모든 page정보를 조회한다. 컬럼의 설명은 위의 주석으로 대체한다.

여기서 알 수 있는 것은 아래와 같다.
1. allocated_page_file_id / extent_file_id는 테이블을 만든 파일 그룹에 속한 File ID 라는 것
2. allocated_page_page_id / extent_page_id 를 통해 1 Extent = 8 Page 라는 것
3. 이전, 이후 Page ID가 없이 그냥 쭉 저장되었다는 것 (순서가 없음)
4. page_level이 모두 0으로 다 같은 레벨의 페이지 라는 것 (트리구조가 아님)
위에서 조회한 page id로 page 단위의 데이터를 조회해보도록 하자.
조회하는 방법은 아래와 같으며, 먼저 traceon을 한 후 조회가 가능하다. 맨처음 select 된 page id = 8을 조회해 보도록 하겠다.
dbcc traceon(3604) --dbcc tracestatus
-- DB Name, File ID, PAGE ID, show mode (0 : header, 1: row, 2: page, 3: column/row)
dbcc page ('BAN_DB', 3, 8, 3) --with tableresults
dbcc traceoff(3604)
조회를 하면 아래와 같은 결과를 볼 수 있는데, Page의 구조는 Header - Body - Offset 순으로 8 byte를 나눠가진다.
맨 상단에 PAGE HEADER가 조회된다.
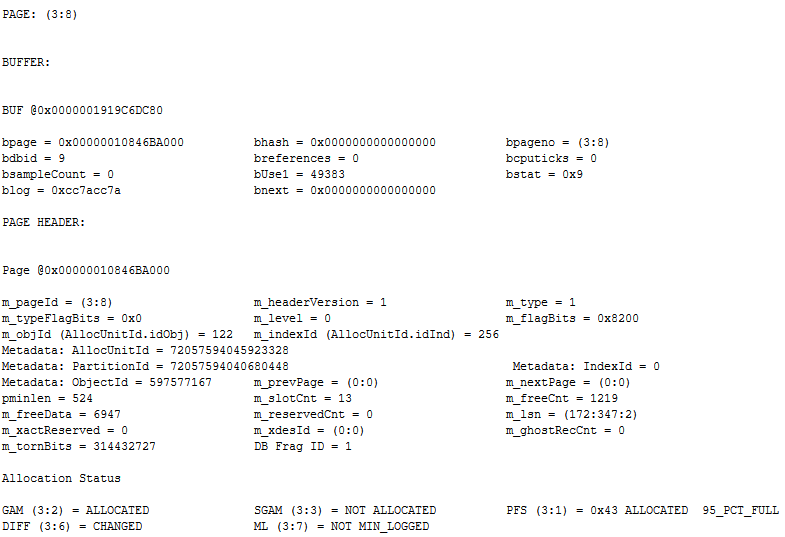
해당 페이지에 대한 정보를 알 수 있는 Header 부분이다.
딱 보면 바로 알 수 있는 값도 있고, 뭘 의미하는지 아리송한 값도 있는데 자세한 내용은 나중에 알아보도록 하자.
다음으로는 Body부분이다. 실질적으로 데이터가 저장되어있는 부분이다.

Page의 첫 데이터 ( Slot 0 )의 값이다. 각 컬럼과 컬럼 별 데이터 값을 저장한 것을 볼 수 있다.
CTS의 경우 char(500)으로 컬럼을 생성하여 빈값까지 저장하고 있는 것을 알 수 있다.
Index Page 알아보기
Data Page의 값을 한번 보았으니 Index Page에 대해서도 한번 알아보도록하자.
indid 2의 값이 우리가 만든 인덱스인 것은 확인했으니 해당 ID의 page들에 대해 조회해본다.
-- page 정보 조회
select allocated_page_file_id, -- File ID
allocated_page_page_id, -- Page ID
previous_page_file_id, -- 이전 File ID
previous_page_page_id, -- 이전 Page ID
next_page_file_id, -- 다음 File ID
next_page_page_id, -- 다음 Page ID
page_level, -- Page LV ( 0 : leaf page)
page_type_desc, -- Page 형태
extent_file_id,
extent_page_id,
page_type
from SYS.DM_DB_DATABASE_PAGE_ALLOCATIONS(db_id('BAN_DB'), -- db id
object_id('XTMP_TEST_IDX'), -- table id
2, -- index id
null, -- partition id
'detailed') -- limited : 제한적 정보 / detailed : 많은 정보
order by page_level desc,
isnull(page_type_desc, 'XX') desc,
allocated_page_file_id,
allocated_page_page_id
위에서 한번 조회해 보아서 알게된 정보들이 있지만, 조회된 내용이 조금 다른 값들이 있다.

다른 값들의 정보는 아래와 같다.
1. 이전, 이후 File, Page ID가 저장되어있다. (순서가 있다)
2. page_level이 모두 0이 아닌 상위값(1)이 하나 있다. (트리구조, level이 제일 높은 값이 root이다)
3. root page에는 이전, 이후 page 값이 없다.
위에서 확인한 정보의 root page부터 조회해 보도록하자.
dbcc traceon(3604) --dbcc tracestatus
-- DB Name, File ID, PAGE ID, show mode (0 : header, 1: row, 2: page, 3: column/row)
dbcc page ('BAN_DB', 4, 26, 3) --with tableresults
dbcc traceoff(3604)root page를 확인해보면 아까와는 다른 결과를 얻을 수 있다.

현재 보고 있는 page의 정보는 root page의 정보로 ChildFileID / ChildPageID 의 값은 root page 하위 레벨 페이지의 정보이다.
ix_no 값과 heap rid 값을 저장하고 있어 해당 page의 시작 key값을 정의하고 있다.
첫번째 ChildPageID 인 24에 대해 다시한번 조회해보자. (leaf page)
-- DB Name, File ID, PAGE ID, show mode (0 : header, 1: row, 2: page, 3: column/row)
dbcc page ('BAN_DB', 4, 24, 3) --with tableresultskey값에 맞게 정렬된 데이터를 볼 수 있다,

index의 의미에 맞게 index key값으로 정렬이 되어있다.
그중 heap rid를 통해 데이터를 찾아갈 수 있게 함께 저장되어있는 모습이다.
우리가 실행 계획을 볼때 index scan 후 RID Lookup은 이렇게 Leaf Page에 저장되어있는 RID를 통해 이루어지는 것이다.
추가 테스트
데이터가 저장되어있는 Page, Index 의 트리구조의 root 부터 leaf까지의 Page를 모두 조회해 보았다.
테스트를 진행하다보니, 과연 이 상태에서 Clustered Index 를 생성한다면 어떻게 될까? 라는 궁금증이 생긴다.
기존의 데이터 용량은 위와 같이 차지하고 있었으나, 클러스터 인덱스를 만든다면?
-- 클러스터 인덱스 생성
create clustered index X_CL_IDX on XTMP_TEST_IDX (CL_NO) on INDEX_02;
용량의 변화가 느껴지는가?
Heap Table 의 데이터가 위치하던 DATA File Group의 사용량이 줄었으며,
Clustered Index가 위치한 INDEX_02 File Group의 사용량이 증가하였다.
또한 Index가 위치하던 INDEX_01 File Group의 사용되지도 않는 전체 사이즈가 증가하였다.
이는 인덱스가 temp로 복사되어 변경 후 이전 것은 삭제되었음을 알 수 있는 점이다.
-- Index ID
select *
/*
id, -- Object ID
indid, -- Index ID (0 : 힙 테이블, 1 : 클러스터 인덱스, 2~250 : 논클러스터 인덱스)
name, -- Index Name
*/
from SYS.SYSINDEXES with(nolock)
where id = object_id('XTMP_TEST_IDX')
인덱스 정보를 확인하면 아까의 indid 0 (Heap Table) 이 없어지고 indid 1 (Clustered Index)이 생겼음을 확인할 수 있다.

Comment
이렇게 Heap Table의 Page에 대해서 한번 파헤쳐보았다.
다음으로는 Clustered Index의 Page와 Page의 변경에 따른 Index정렬에 변화 에 대해서 순차적으로 확인해보는 시간을 가져보겠다.

'DATABASE > MsSQL' 카테고리의 다른 글
| [MsSQL] SQL Server 2019 Standard 기본 설치 (Windows Server) (0) | 2024.04.20 |
|---|---|
| [MsSQL] Openquery insert - 다른 데이터베이스의 테이블에 데이터 저장하기 (0) | 2024.04.16 |
| [MsSQL] Openquery select - 다른 데이터베이스 데이터 읽고 저장하기 (0) | 2024.04.09 |
| [MsSQL] 테이블 정의서 만들기 - 쿼리로 추출하기 (0) | 2024.03.26 |
| [MsSQL] Database Backup이란? - Full / Differential / Log Backup (0) | 2024.02.24 |
| [MsSQL] 모든 DB에 한번 쿼리 던지기 / DB 모를 때 (SP_MSFOREACHDB 활용하기) (0) | 2024.02.13 |
| [DBA][MsSQL] Index 사용량 조회 / 미사용 Index 확인 (0) | 2024.02.10 |
| [MsSQL] Database 복구 모델 - Simple, Full (단순 모델, 전체 모델) (0) | 2023.10.16 |



