Galera Cluster 동기화 전송 지연
Galera Cluster를 구성할 때 제일 중요한 점이 하나 있다.
바로 각 Table에 PK가 무조건 있어야 한다는 것인데, 이는 PK값을 통해 해당 테이블의 값을 찾아 변경/삭제를 하여 동기화를 하기 때문이다.
원래 Galera Cluster를 구성할 때 모든 테이블에 PK를 조사하여, 없으면 생성 후 구성을 하였는데
간단한? 데이터 작업을 하기위해 Temp Table을 만들고 데이터를 삭제하는 과정에서 PK를 누락하여,
갈레라 클러스터 간의 동기화 지연 이슈로 서버가 먹통이 되었다.
이 장애의 내용부터 시작해 해결방법 그리고 얼마나 걸렸는지, 그 후속 테스트까지 간단하게나마 글로 남겨보도록 한다.
장애 내용
Galera Cluster가 구성되어있는 MariaDB에 PK가 없는 Table의 데이터를 delete 하여, Cluster간의 데이터 전송에 있어 지연으로 인해 장애발생
PK 가 없는 약 100만 건의 row를 가지는 TABLE의 특정 조건의 delete 문을 실행하였다.
Galera Cluster에 대해 미처 생각하지 못하여, PK를 만들어야 겠다는 생각을 하지 못하고 진행하였다.
Master Cluster 상황
일정량의 데이터 삭제가 진행되다가 어느 순간부터 트랜잭션들이 commit되지 못 하고
트랜잭션을 실행한 Master Cluster 에서는 waiting for certification 의 상태 값으로 이후 트랜잭션들이 대기하였다.
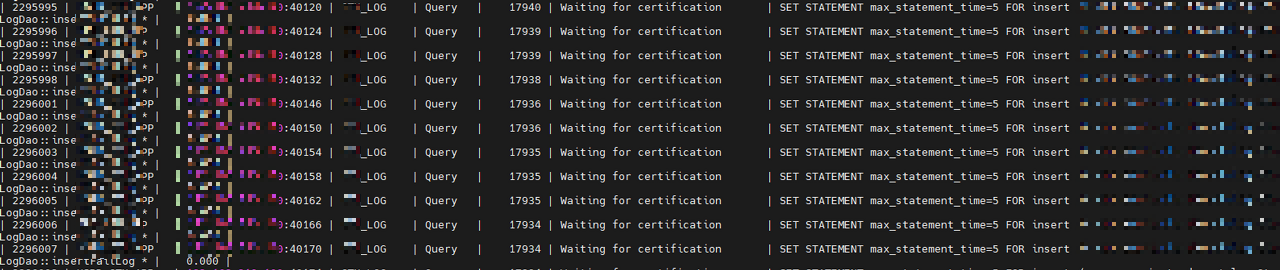
이 상황까지만 해도 Cluster의 PK없는 delete문이 문제일거라 생각 못했다.
Error Log 파악
답답한 마음에 뭐라도 찾아보고자 Error Log를 찾아보다보니 아래와같은 메시지를 발견 할 수 있었다.
[Warning] WSREP: Failed to report last committed c9e93d36-e569-11ed-8c0d-06cb859f89b4:2014834601, -110 (Connection timed out)
에러 메시지를 통해 이리저리 찾아보다보니, 클러스터의 문제라는 글을 발견 후 그때부터 문제 파악의 속도가 났다.
[MDEV-17550] Improve WSREP's "Failed to report last committed" warning message - Jira
When a Galera Cluster is under a lot of load, it's common for the log to have warning messages like: [Warning] WSREP: Failed to report last committed 211651504, -4 (Interrupted system call) or [Warning] WSREP: Failed to report last committed 342386158, -11
jira.mariadb.org
Slave Cluster 상황
동기화 받을 Slave Cluster에서는 Delete_rows_log_event::find_row 라는 상태로 트랜잭션이 멈춰있는 상태였다.

이렇게 동기화 받을 Cluster에서 동기화 지연 이슈가 발생하여, 트랜잭션이 마무리 되지 못하는 문제로 발전하게 되었다.
장애 조치 내용
여러 인터넷의 글을 찾아본 결과
클러스터의 동기화 지연이 자연적으로 해소되기를 기다리거나, 서비스를 재기동해야 한다고 한다.
자연적으로 지연이 풀리기를 약 5시간 가량 기다렸으나, 지연 해소가 되지 않기에 Cluster를 재기동 하기로 결정하게 되었다.
해당 조치를 하기 전 서비스에 접근하는 다른 api들을 중지 시킨 후 작업을 진행하였다.
해당 내용을 시간대 별로 정리해본다.
22:48 Cluster 1 MariaDB 서비스 중지
systemctl stop mariadb
둘중 하나의 MariaDB 서비스를 중지 해야 할것 같은데,
Master인 Cluster 1의 서비스를 중지하냐 Slave인 Cluster 2의 서비스를 중지하냐 고민을 하게되었다.
Cluster 1에 모든 트랜잭션이 쌓여있고, Cluster 2는 수신받고 있는 delete문만 대기상태이므로
Cluster 1의 트랜잭션을 정리하는게 좋을 것 같아 Cluster 1을 중지시키기로 결정하였다.
- Cluster 1 MariaDB 종료 후 Master 변경 완료 ( Cluster 1 => Cluster 2 )
- Cluster 2에 수신 받고 있는 Delete 트랜잭션 그대로 대기 상태
- 서비스 중지 작업 중 Cluster 2(Master가 됨) 에 다른 Insert 쿼리가 들어와 Kill을 시켰으나 해당 Kill도 대기 상태 (Waiting to execute in isolation | kill query 2295638)
22:58 Cluster 2 MariaDB 서비스 중지
systemctl stop mariadb
Cluster 2의 Delete 트랜잭션이 해소가 되지 않아 Cluster 2의 MariaDB도 종료하기로 결정 후 MariaDB 서비스를 중지 시켰으나 정상적으로 완료가 되지 않았다.
23:07 Cluster 1 MariaDB 단독 실행 (Cluster 해제)
결국 Cluster 1, 2로 구성되어있는 MariaDB 두대 전부 서비스 중지를 시켰으나,
Cluster 1은 정상적으로 중지가 되었고 Cluster 2 는 중지가 되고 있는 중이다. (정상적이지 않음)
다시 Cluster 1의 MariaDB 서비스를 실행 하기로 결정하였는데, 갈레라 클러스터를 해제하여 단독으로 실행 하기로 하였다.
/etc/my.cnf.d/server.cnf 에서 Galera 옵션 전부 주석 처리하였여 단독사용으로 옵션을 바꾸었다.
해당 옵션들은 아래의 설치글에서 참고 바란다.
[MariaDB][Linux] Galera Cluster 설치 - 이중화 / HA 구성
Intro 안녕하세요. 초보 DBA 다뉴입니다. 오늘은 저번에 설치해본 MariaDB를 이중화하는 내용에 대해서 한번 다뤄볼까하는데요. MariaDB를 아직 설치 못하신 분은 아래의 링크를 참고해주세요 :) [MariaDB
da-new.tistory.com
systemctl start mariadb
MariaDB 서비스를 다시 실행하니 바로 정상 실행이 완료되었다.
실행 상태를 확인하고자 maxscale 서버에서 서버상태를 확인해보았다.
maxctrl list servers
Cluster 1은 정상적으로 Running의 상태가 되었고, Cluster 2는 중지 명령어를 날렸으나 아직도 Running 상태가 유지되고있다.
클러스터 모드가 제대로 해제되었는지 다시 확인하고자 mariadb status 상태를 확인해보았다.
show status like 'wsrep%';
Cluster 1이 단독 실행이 되었음을 확인할 수 있었고,
해당 데이터베이스에서 문제가 되는 Table을 drop하기로 결정하였다. (임시 작업용이라 삭제가 가능했음)
drop table [table_name];
23:11 Cluster 2 Server 리붓
22:58 경 중지를 하였던 Cluster 2가 정상적인 종료를 하지 못하고 있어 서버의 리붓을 결정하였다.
reboot
리눅스 서버를 리붓하였음에도 OS부팅이 오랜시간 되지않아 불안에 떨며 지켜보게되었다.
23:34 Cluster 2 Server 재기동
23:11 경 리붓하였던 Cluster 2 서버가 약 20여분만에 재기동에 성공하였다.
30분 이상 재기동이 되지않을 경우 포기하려 했었는데... 다행이였다.
클러스터 서버들은 만약을 대비해 재기동시 MariaDB가 자동으로 실행되지 않도록 설정해두었어서,
서버가 재기동되어도 MairaDB서비스가 올라오지 않았다.
MariaDB가 기동되지 않은 상태에서 해당 서버도 클러스터를 해제 후 단독으로 실행 하기로 하였다.
위와 동일하게 /etc/my.cnf.d/server.cnf 에서 Galera 옵션 전부 주석 처리하여 MariaDB 단독실행 할 수 있도록 설정하였다.
갈레라 클러스터 모드를 해제 후 MariaDB 서비스를 단독으로 실행 시키는데 성공하여, 위와 같이 문제가 되는 테이블을 drop 하였다.
23:40 Galera Cluster Mode로 실행 Cluster 1 → Cluster 2 순으로 재기동
다시 모든 MariaDB 서비스를 중지 시킨 후 갈레라 클러스터 모드로 실행하기로 하였다.
주석처리 했던 Galera 옵션을 다시 복구 시킨 후, Cluster 1 부터 순차적으로 실행하기로 하였다.
galera_new_clusterCluster 1의 서비스 실행은 galera_new_cluster 명령어를 통해 Galera Cluster모드로 실행을 하였으나, 서비스가 올라오지 않았다.
Master Cluster에 대해 명시 하고자 /data/mariadb/mysql/grastate.dat 파일을 수정 후 다시 실행하였다.
vi /data/mariadb/mysql/grastate.dat
------------------------------------
safe_to_bootstrap: 1 ## 0 → 1로 변경
파일 수정 후,
Cluster 1에 대해 galera_new_cluster 명령어로 클러스터 모드 실행에 성공
galera_new_cluster
Cluster 2에 대해 systemctl start mariadb 명령어로 Mariadb 서비스 실행
systemctl start mariadb
Cluster 1,2 모두 서비스 실행에 성공했으나, max sacle을 통해 클러스터의 상태를 확인하니 일관성이 깨져있는 것을 알 수 있었다. (Inconsistent)
maxctrl list servers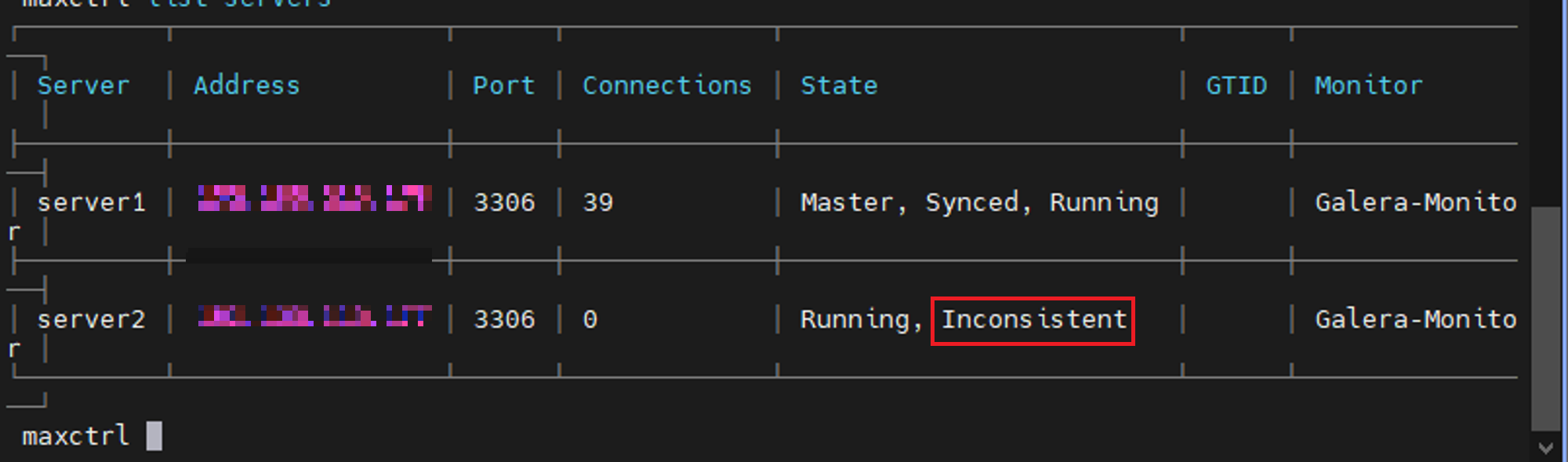
Cluster 2 의 MariaDB에 접속하여 select문을 실행시 오류가 발생하는 것을 확인

Cluster 1 에서 ' show status like '%wsrep_%' ' 명령어로 확인 시 Cluster 2 와 연결되지 못한 것을 확인
show status like 'wsrep%';
24:17 두번째 Galera Cluster Mode로 Cluster 1 → Cluster 2 순으로 재기동
시간을 두고 기다려보았으나 일관성을 맞추지 못하기에 다시 재기동을 하기로 결정하였다.
Cluster 2, Cluster 1의 순서대로 MariaDB 서비스를 중지시켰다.
systemctl stop mariadb
다시 Cluster 1 의 MairaDB 서비스 재기동 -> 정상 기동 완료
galera_new_cluster
이어서 Cluster 2의 MariaDB 서비스 재기동 -> 서비스 기동 중 상태 유지
systemctl start mariadb
Cluster 2의 MariaDB가 바로 올라오지 않고 대기상태에 빠졌는데,
Cluster 1에서 Galera 설정 상태를 확인하니, 요번엔 연결상태가 되어있었다.
show status like 'wsrep%';
Cluster 1의 서버에 프로세스 상태를 한번 확인해보았다.
ps -eaf | grep mysql
Cluster 2와 동기와 중인 상태로 판단이 되었다.

24:35 Cluster 2 Mariadb 재기동 성공 - 정상 동작
Cluster 1과 Cluster 2가 동기화 중인 것으로 판단이되어, 한번 기다려 보기로하였는데
약 20여분 후 동기화를 끝마치고 Cluster 2의 MariaDB가 기동에 성공하였다.
DML을 테스트하여, 각 Cluster 상태 및 MaxScale동작을 확인 하여 정상임을 체크하였다.
select @@hostname; -- slave
insert into ~ values (@@hostname); -- master
후기
꽤나 오랜시간 서비스 장애 및 마음을 조리며 작업을 하였습니다.
기본이고 간단하지만 크게 신경쓰지 않았던 부분인 PK를 만드는 것부터 시작한 이 사태에 대해 많은걸 다시한번 배웠습니다.
Galera Cluster를 구성하기 전 시스템 장애가 발생하면 어떤식으로 대처하고 어떻게 동작하는지 테스트를 진행 후 구성을 했었는데요.
막상 장애 상황이되니, 이 서비스를 내려도되나? 이런 선택을 해도 되나? 싶어서 더욱 어려웠던 것 같습니다.
추가로 테스트를 진행한 내용에 대해서는 다음 포스팅에 작성하도록 하겠습니다.
감사합니다.

'DATABASE > MariaDB' 카테고리의 다른 글
| [MariaDB] User DDL - 사용자 생성, 변경, 삭제 (0) | 2024.04.06 |
|---|---|
| [MariaDB][Linux] Log Setting (2) - Error Log 설정하기 (0) | 2024.02.02 |
| [MariaDB][Linux] Log Setting (1) - General Log, Slow Query Log 설정하기 (1) | 2024.01.19 |
| [DBA][MariaDB] 사용자 계정 접속 잠금, 비활성화(?) - ACCOUNT LOCK (0) | 2024.01.12 |
| [MariaDB][Linux] 보안 설치 - mariadb-secure-installation (0) | 2023.12.29 |
| [MariaDB] Password 복잡도 설정 - simple_password_check Plugin (3) | 2023.12.06 |
| [MariaDB][Linux] MaxScale 설치 - Load Balancer (1) | 2023.08.03 |
| [MariaDB][Linux] Galera Cluster 설치 - 이중화 / HA 구성 (1) | 2023.07.26 |



